Title: Characterization and Analysis of Text-to-Image Diffusion Models
Venue: IEEE Computer Architecture Letters (CAL), 2024
Author: Eunyeong Cho, Jehyeon Bang, and Minsoo Rhu (KAIST)
[ 무엇에 관한 논문인가 ]
- Stable Diffusion에서 생성하는 이미지의 해상도가 커질수록 Attention의 계산 복잡도가 지수승으로 증가함을 분석함.
- Attention에서 Score matrix가 sparse하게 near-zero인 것을 관측하고, Approximate attention mechanism을 제안해 약 70%의 FLOPs를 줄임.
- 실제 GPU에 이 메커니즘을 적용하면 연산량이 줄어들지만, 오히려 데이터 재사용이 줄어들면서 메모리 접근이 많아짐. 특히 Score matrix의 unstructured sparsity pattern으로 인해 메모리접근이 비효율적으로 되면서 Flash-Attention2에 비해 큰 사이즈 이미지 생성에서 성능이 떨어짐. 작은 사이즈에서는 아웃퍼폼함.
- 이러한 한계점을 해결하기 위해 Future Work에서는 1) GPU 소프트웨어 최적화, 2) 혹은 이러한 연산에 최적화된 가속기를 제안할 수 있음
[ Diffusion Model ]
Diffusion Model 이란 Diffusion Process를 따르는 생성형 AI 모델을 일컫는데, Diffusion Process는 원본 이미지에서 점차 noise가 추가되는 과정이고, Model이 새로운 이미지를 만드는 방법은 Noisy Image로 부터 noise를 추측하여 제거하는 Denoising Process를 통해 새로운 이미지를 생성하는 능력을 배움.

본 논문은 이러한 Process를 따르는 다양한 Diffusion Model 중에서도 Stable Diffusion (2.1) 을 채택하였음.
[ Stable Diffusion ]

우선 모델은 randon noise(zt) 로 부터 시작함. Stable Diffusion은 U-Net 구조를 따라 설계되어 있는데, 각 Denoising Step에서 Copmaction (Down-scaling)과 Expansion (Up-scaling) 과정을 거침. 각 구조에서 연산은 ResBlock과 TransformerBlock으로 이루어져 있으며, 유저의 Input Prompt는 CLIP Encoder를 거쳐 Cross-attention의 입력으로 사용되어 생성하고자 하는 이미지의 조건을 부여하는 형태.
CLIP Encoder: CLIP은 OpenAI 에서 개발한 신경망 구조로 Text와 Image를 결합해주는 구조임. 이러한 Encoder를 통해 유저의 Input Text가 생성하려는 Image에 반영될 수 있는 것
Cross-attention: Attention은 Q,K,V로 이루어져있는데, Q,K,V를 생성할 때 다른 Input이 들어오면 Cross-attention이라고 부름. 반면, 다 같은 Input으로 생성될 경우 일반적인 Self-attention. (다 같기 때문에 Self)
이러한 Denoising Step은 User가 설정하는 바에 따라 다르지만 일반적으로 25~50회 수행됨.
중요한 것은 Compaction 과정에서 latent vector의 height/width가 줄어들면서 channel은 늘어나는 반면 반대로 Expansion 과정에서는 height/width는 늘어나면서 channel은 다시 줄어듦.
논문에는, 이 부분에서 expansion 과정동안 channel이 다시 "늘어난다"라고 쓰여있는데 오타 같음. 추후에 수정될 수 있음.
또한 OpenAI의 동영상 생성 모델인 Sora의 구조가 아직 밝혀지진 않았지만 Diffusion-Transformer(DiT)라고 추측되고 있는데 본 논문에 쓰인 Stable Diffusion은 U-Net 구조에 기반하지만, 반대로 DiT 계열들은 U-Net 구조를 따르지 않음. 그렇기에 본 논문의 해석결과를 Diffusion Model로 넓게 생각하기 보다는 U-Net 계열의 Diffusion Model로 생각해야할 것 같음.
그리고, 논문 뒷 부분 실험을 읽으며 헷갈려던 부분을 써보자면 논문에서 Image Size를 512x5125와 같은 크기로 설정하는데 이는 생성된 Output Image 사이즈이고, Stable Diffusion의 경우 64x64와 같은 random latent image에서 생성을 출발함. 즉, 512x512 사이즈로 시작하는게 아님. 찾아보니 보통 이 차이가 8배 라고 함. 실험 Fig. 10 의 x축이 Pixel Dimension인데 이는 생성하고자 하는 이미지 크기의 1/8인 random latent image size인 것 같음.
[ Characterizations ]
먼저 본 연구에서는, A100 GPU를 이용해 Stable Diffusion 2.1 버전 모델에 대한 특징 분석 실험을 진행함.
실험을 진행하며 발견한 관찰점에 대해 Observation 1) 2) 3) 으로 정리하겠음.

차근차근 분석을 진행해보자면,
Observation 1) 큰 이미지를 생성할수록 self-attention이 execution time에 큰 영향을 미침
먼저 (a)를 보면 붉은 선인 Latency가 증가하고 있으며, Transformer Block의 비중이 커짐. (b)는 TransformerBlock의 Breakdown 인데, Self-attention의 비중이 커지고 있고, (c)에서는 그 중에서도 Attention의 비중이 가장 dominant 해지는 모습을 보여줌
Self-attention 과정 자체의 연산 복잡도가 O(N^2) 인데, 본 모델에서 N은 input activation map의 width인 W의 제곱에 비례함. 즉 O(W^4)가 되어 input activation map이 커질수록 연산량이 기하급수적으로 증가하는 구조임. 위 Figure를 통해 이러한 영향을 확인할 수 있음.
여기서 말하는 activation map size는 input latent로부터 유도되는 것인데, input latent size는 생성하려는 이미지 크기의 1/8로 생각하며 읽었음.
간단히 계산을 해보자면, 2048x2048 기준으로 Self-attention의 Attention은 약 57%를 차지함 = 0.75 x 0.8 x 0.95.
반면 512x512 기준으로는 4.5%를 차지함 = 0.5 x 0.3 x 0.3.
즉, 이 논문이 고려하고 있는 부분은 큰 이미지를 생성할 때의 퍼포먼스로, 약 57%를의 Execution time을 차지하는 부분을 완화하고자 하는 것.
Obervation 2) Score 행렬 S는 희소화(Sparsification) 하는 것에 적합하다.

위 Figure를 보면 Score 행렬 S에서 pruning이 적용가능한 대상이 많다는 것을 확인할 수 있음. 본 논문에서는 해당 요소들에 pruning을 적용해 연산량을 줄이는 방법을 적용하고자 함. 이전 연구들 또한 비슷한 방법론을 취해왔음 [4][5].
- S에 pruning을 적용하면 --> Attention = S x V 가 dense GEMM 에서 SpMM (Sparse MM)이 되어 연산량이 감소할 것.
- 그리고 S에서 near zero가 될 대상을 S=QxK 계산전에 알 수 있다면, QxK는 Sampled Dense-Dense MM (SDDMM)이 되어 연산량을 더 줄이는 것이 가능함.
여기서 말하는 SDDMM의 동작 방식은, 추측하기로는, 모든 QxK를 곱하는 것이 아니라, pruning을 적용한 S를 기반으로 계산이 유효할 QxK 요소들만 계산함으로써 연산량을 줄이겠다는 것 같음. 당장 이해못해도 뒷 부분에서 계속 설명함.
Observation 3) Score 행렬 S의 희소성은 Denoising Process 동안 점진적으로 변화함.

Figure를 보면 흰 부분이 near-zero elements를 의미함. Step이 진행될수록 흰 부분이 늘어나는데, 그 말은 검은 부분(non-zero)이 흰 부분(near-zero)로 변화한다는 것임. 즉, 다음 단계에는 더욱 Sparsity가 증가할 것이기 때문에, 현재 단계의 Sparsity 정도를 다음 단계에 적용하더라도 큰 무리가 없음. 이러한 방식으로 다음 k 번의 step 동안 socre 행렬 S의 sarsity 정도를 예측하는 방법을 제안함.

위 Figure는 본 논문이 제안하는, Approximate attetion mechanism 이며, 다음과 같이 정리할 수 있음.
- Step i 에서 Score 행렬 S를 원래 처럼 dense MM (QxK) 으로 만듦
- Score 행렬 S에 pruning을 적용하고, 여기서 얻어진 sparsity pattern을 다음 k 번의 step 동안 QxK에 적용함.
- k 번의 step 동안 온전히 QxK를 계산하는 것이 아니라, sparsity pattern에 기반해 계산할 애들만 계산함. 즉 여기서 1차 연산량 감소함.
- 그리고 모든 SxV는 SpMM으로 바뀌며 여기서 2차로 연산량이 감소함.
- 매 k+1 step마다 Score 행렬을 온전히 계산하여 다음 k step 동안 재사용함.
위와 같은 방법을 따라 SSDMM, SpMM에서 연산량을 감소하도록 설계되었음. 이 방법에 따라 계산했을때,
- 512x512, k=4 --> 67.92% attention 연산량 감소,
- 768x768, k=4 --> 79.46% attention 연산량 감소함.
약 70% 정도의 attention 연산량이 감소한다고 가정했을 때 다양한 이미지 크기에서 전체 연산량 감소 효과는 다음 Figure와 같음.
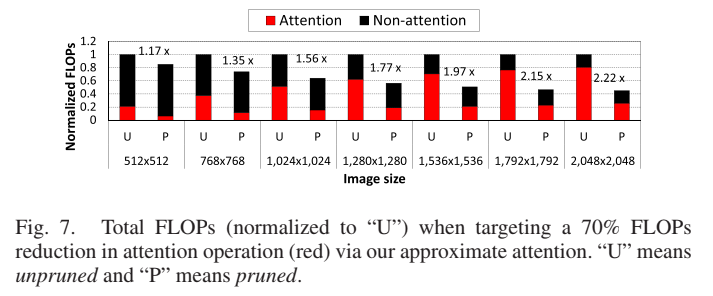
2048x2048과 같은 큰 이미지를 생성하는 경우 2배 이상의 연산량을 감축시키는 효과가 있음. 이렇게 연산량을 날려버리면 성능이 떨어질 수도 있을텐데, output 성능엔 큰 영향을 미치지 않음.

[ Challenges ]
본 논문에서는 이러한 Approximate attention 방법을 Flash-Attention 스타일로 구현하고, FlashAttention-2와 비교하였음 [3].

먼저 위 Figure의 x축인 Pixel Dimension은 Stable Diffusion 작동 방식에 따라 생성하려는 이미지의 1/8 이라고 생각하였음. 즉, 바꿔보자면 순서대로 128x128, 256x256, 512x512, 1024x1024를 의미할 것이라고 추측함.
위 Figure의 (c)가 FlashAttention 대비 성능을 나타내는데, 128x128과 같은 작은 이미지 그리고 Head 숫자가 적을 때 67% 정도의 성능 향상을 보임. 반면 그 외에 이미지가 커질 때는 상당히 성능을 내지 못하고 있음.
이 결과를 이해하기 위해서는 computer-bound와 memory-bound를 이해해야 하는데, 컴퓨터가 "계산"을 하기 위해서는 "데이터"가 필요하고, "데이터"는 메모리로부터 캐시로 읽어짐. 컴퓨터는 "캐시"에 있는 데이터를 대상으로 계산을 수행함.
캐시 접근은 매우 빠르지만 보통 작기 때문에 많은 데이터를 담을 수 없고, 데이터가 캐시에 없다면 메모리에 접근해 데이터를 가져와야 하는데, 메모리에 접근하는 것은 캐시에 비해 매우 느림.
본 실험의 비교 대상인 FlashAttention은 Attention 행렬을 Tiling 하여 캐시에서의 Reuse를 높였음. 즉 메모리 접근 자체를 줄이도록 최적화한 것임.
여기서 일반적인 컴퓨팅 특징을 다음과 같이 2가지로 구분할 수 있음.
- Compute-bound: 데이터는 가져왔는데 연산이 너무 오래걸리는 경우
- Memory-bound: 데이터 접근이 잦아 새로운 데이터를 계속 읽어와야 해서 연산기는 놀고 있는 경우
다시 본 연구로 돌아와, Approximate attention 기법을 GPU에 적용하면 다음과 같은 일이 발생함.
- Approximate attention으로 인해 SDDMM, SpMM 으로 연산량이 많이 줄었음 (compute-bound 완화).
- 이 효과를 누리기 위해서는, fine-grained Tiling 으로 불필요한 아웃풋 계산을 피하는것이 필수적임.
- 근데 희소화가 적용된 작은 타일에서는 재사용이 많이 줄어들기 때문에, 반대로 계속 새로운 데이터를 읽어와야 함(memory-bound 심해짐).
즉, 정리하자면 Approximate attention을 통해 Stable Diffusion의 연산량을 줄이는 시도를 하였는데, 연산량을 줄였더니 반대로 메모리 접근이 잦아져 memory-bound화 되었다는 것.
단순히 메모리 접근이 잦아졌다는 것은 아니고, 1) Sparsity가 더해지기 때문에, 연속적인 메모리 접근이 아니라 랜덤한 메모리 접근을 할 것이기 때문에 더욱 비효율적으로 메모리 접근, 2) 여기에 더해 타일링으로 인해 데이터 재사용이 낮아짐
메모리 접근을 쉽게 생각하면 "준비->접근->끝"임. 이미 "준비"가 되어있는 경우 "접근"만 하면 되는데, "준비"가 안되어있는 경우, "준비"는 1개만 할 수 있어서 다른 애를 "끝"내야 함.
이때, "접근" 자체는 오래 걸리지 않지만 각각의 "준비"와 "끝"이 오래 걸림. 그렇기 때문에 랜덤하게 메모리 접근을 하게 되면 새롭게 준비하는 경우 혹은 이미 준비되어있는 애를 끝내고 내가 원하는 애를 준비시켜야 하는 경우가 잦을 것이기 때문에 단순히 접근하는 것보다 시간이 더욱 많이 걸리게 됨.
본 논문은 이러한 한계점을 지적하며 Future work로 다음을 남겨둠.
- 이러한 문제를 해결할 수 있는 GPU 소프트웨어를 구현하는 것
- Approximate attention에 최적화된 가속기를 설계하는 것
[ Reference ]
[3] T. Dao, “FlashAttention-2: Faster attention with better parallelism and work partitioning,” 2023, arXiv:2307.08691.
[4] L. Lu et al., “Sanger: A co-design framework for enabling sparse attention using reconfigurable architecture,” in Proc. Int. Symp. Microarchitecture, 2021, pp. 977–991.
[5] H. You et al., “ViTCoD: Vision transformer acceleration via dedicated algorithm and accelerator co-design,” in Proc. Int. Symp. High- Perform. Comput. Archit., 2023, pp. 273–286.
모든 레퍼런스를 담지 않고, 표시할 레퍼런스만 논문에서의 번호와 동일하게 사용함.